Written by Atharva Jagtap
Wednesday, May 13, 2026
Buildings AI: From Chaos to Clarity - Three Architectures and What We Finally Got Right
By
Atharva Jagtap


We've spent two years trying to teach an AI to understand a building — not to describe one. Understand the way a senior mechanical engineer does: glance at a floor plan and immediately see the load distribution, know which air handler serves which zones, feel in your gut when something is undersized.
Buildings AI is a platform for load and energy simulation — engineers use it to model how a building will perform before it's built. One feature lets a user design an HVAC system in natural language; that design feeds directly into the simulation engine. That feature is what this post is about.
This domain doesn't forgive fluency. A confidently wrong LLM is worse than a useless one — it produces specs that pass casual review and silently break the simulations they were supposed to feed. The industry isn't slow to adopt AI for lack of interest. It's slow because correctness is non-negotiable here.
We got the architecture wrong twice before we understood what we were actually building.
Why This Domain Breaks Naive Agentic Approaches
HVAC design is an unforgiving target for agentic AI. Four constraints shape everything that follows.
The output must be structured and technically valid. It's not enough to describe an HVAC system in natural language. The output is the input to the simulation engine — component types, parameters, connection topologies, all machine-readable, all within tolerance. A hallucinated component name, a missing connection, a parameter out of range: any one of these silently breaks the simulation, or worse, runs it and produces numbers a human might trust. There is no partial credit.
The interdependencies are deep. Components don't exist in isolation. An air handling unit connects to chilled water plants, hot water plants, terminal units, and zones. Each connection has rules — many of which live in the heads of engineers who've spent decades learning what fits with what. The AI has to reason for a graph, not a list.
The domain knowledge lives in data, not text. HVAC design knowledge is encoded in structured databases: component definitions, sizing tables, connection rules. It is not in the documents an LLM was trained on. You cannot prompt your way through this. The system needs real, authoritative data access and must treat it as the source of truth, not a hint.
The input is underspecified. "I want a VAV system with a central plant" carries maybe 10% of what the simulation engine needs. The AI must ask the right questions, make defensible assumptions, and flag conflicts. It has to know when it's guessing.
All of this means architecture matters enormously. Sloppy architecture doesn't stay sloppy in one place — it gets amplified through every layer.
Version 01 — Every Agent for Itself
We started where most teams start: mapping product features to agents. A Space Agent for room definitions and zone assignments. A Material Agent for the designer's material library. A Construction Agent for how materials are assembled into walls, roofs, floors. Each self-contained — its own prompts, its own tools, its own logic.
This felt right for reasons that weren't wrong. Separation of concerns is foundational. Smaller agents seemed easier to test and debug. Teams could work in parallel. We were applying a software principle we trusted.
What actually happened is that the agents lived on islands.
Without a shared workflow state, every agent had to carry out the full context of the entire design session. Context grew unbounded; agents bloated with information they only needed occasionally. No orchestration meant no coherence — the envelope is interconnected, but each agent reasoned for its slice in isolation. When a user changed a material, nothing told the Construction Agent its assumptions had shifted. Each agent responded competently to its own prompt. The system as a whole didn't. Adding anything was expensive — each integration was bespoke; the system didn't compose, it accumulated.
"We had hired a roomful of specialists who never attended the same meeting. Each one was competent. None of them produced a coherent design together."
The lesson: isolated agents don't compose. Capability at the agent level doesn't add up to intelligence at the system level without orchestration. Agents without connective tissue are just expensive for API calls.

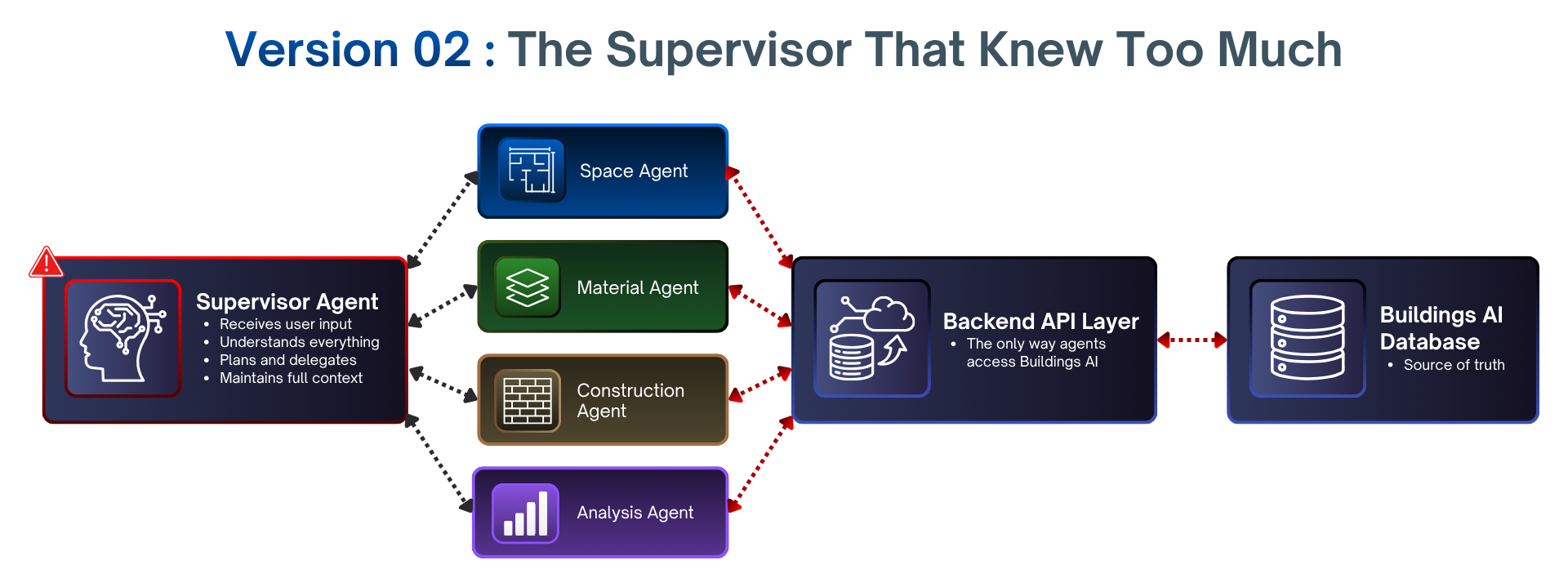
Version 02 — The Supervisor That Knew Too Much
V1 taught us agents who needed coordination. The obvious answer - and what the literature pointed to - was a supervisor.
V2 introduced a central agent built on LangGraph and LangChain. Receive user input, plan, delegate to subagents. The envelope agents became leaner subagents - they no longer carried full session context, just the slice the supervisor handed them. The system had a defined topology. After V1, that legibility alone felt like progress.
But the supervisor became the bottleneck and the single point of fragility. To plan well, it had to understand everything: what each subagent could do, the current envelope state, user history, active constraints. Its promptness and context grew enormously. It made fine-grained decisions about things it shouldn't have needed to know - not because we wanted it to, but because there was nowhere else to put up the knowledge.
Without a shared workflow state, every agent had to carry out the full context of the entire design session. Context grew unbounded; agents bloated with information they only needed occasionally. No orchestration meant no coherence — the envelope is interconnected, but each agent reasoned for its slice in isolation. When a user changed a material, nothing told the Construction Agent its assumptions had shifted. Each agent responded competently to its own prompt. The system as a whole didn't. Adding anything was expensive — each integration was bespoke; the system didn't compose, it accumulated.
The deeper problem, and the one we hadn't seen for a long time, was API coupling.
The agents talked to Buildings AI through backend APIs, not directly to the database. This looked like clean architecture - abstraction layers, clean boundaries. It turned out to be a serious constraint. Whenever the backend changed, the agents broke down. Prompt logic had to be rewritten. Tool definitions are updated. Agent behavior was at the mercy of a layer it didn't own. The agents weren't reasoning about data - they were reasoning about what the API told them about data. That distinction sounds small and is not.
Adding a new capability meant a four-layer change: backend API, agent tools, supervisor understanding, prompts. And Buildings AI evolves constantly. We had built a system that was hardest to change in precisely the area that needed to change most.
Two lessons: API-coupled agents are just backend code with an LLM in the middle. Real autonomy requires data ownership. And a supervisor that must understand schemas, and API contracts isn't planning — it's doing everything.
The Insight — Ownership Is Not Responsibility
After V2 we sat with the problem longer than we usually do. Better supervisor prompts, smarter routing, a thinner API layer — we tried some of that. None of them changed the shape of the failure.
The shift came when we noticed we'd been asking the wrong question. We'd been asking "how do we coordinate agents?" The better question was: "what does each agent own?"
Ownership is different from responsibility. Responsibility is about what you do. Ownership is about what you have authority over — what you can read, write, and decide without asking anyone else. V1 and V2 agents had responsibilities. None had ownership. Every meaningful piece of data lived behind some other layer, and the agents were constantly asking permission to act on information they didn't control. The supervisor wasn't planning — it was negotiating between agents that couldn't act on their own.
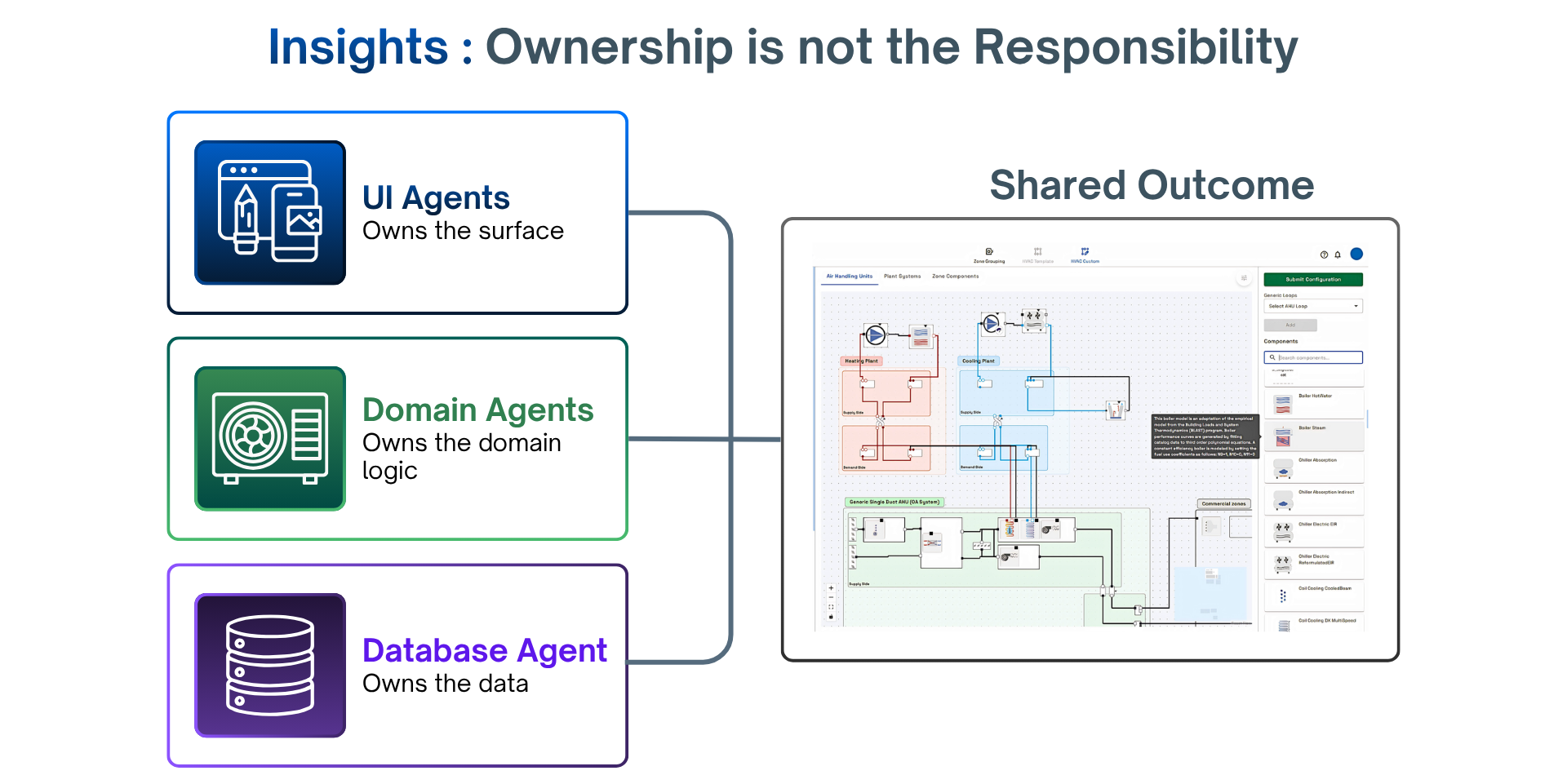
When we stopped thinking about agents as feature modules and started thinking about them as owners, three distinct domains emerged naturally.
Domain agents have deep knowledge of a specific problem area — HVAC, envelope, structural, electrical and plumbing. They know domain rules, component hierarchies, and connection logic. They don't know how the UI is laid out. They don't know how data persisted. Inside their domain, they are autonomous.
UI agents own the surface — what the user sees, how they interact, what their intent means in context. They translate between natural language and structured action. They don't know domain rules or data schemas. They know the user and the interface, and they hand it off to the right domain agent when intent becomes action.
Database agents own data access and persistence — the authoritative interface to everything designed so far in a Buildings AI session. They don't know domain rules or UI. They know the data model end to end, and answer questions about it without anyone else mediating.
The defining property of clean ownership: a change inside one domain does not force changes in another. Database schema changes? Only the database agent updates. New UI interaction pattern? Only the UI agent. New HVAC component type? Only the domain agent. Compare that to V2, where the same changes rippled through four layers.
None of this is new - it's how good software has been designed for a long time. The insight was applying it to the agents themselves, not just the code they sat on top of. When we decided to validate the new architecture, we didn't rebuild the familiar envelope. We started with HVAC — a domain Buildings AI hadn't done with AI yet — and with the data layer, our worst pain point in both prior versions. If the architecture could hold under HVAC's interdependencies and own its data end-to-end, it would hold anywhere.
Version 03 — Proving the Data Layer with HVAC
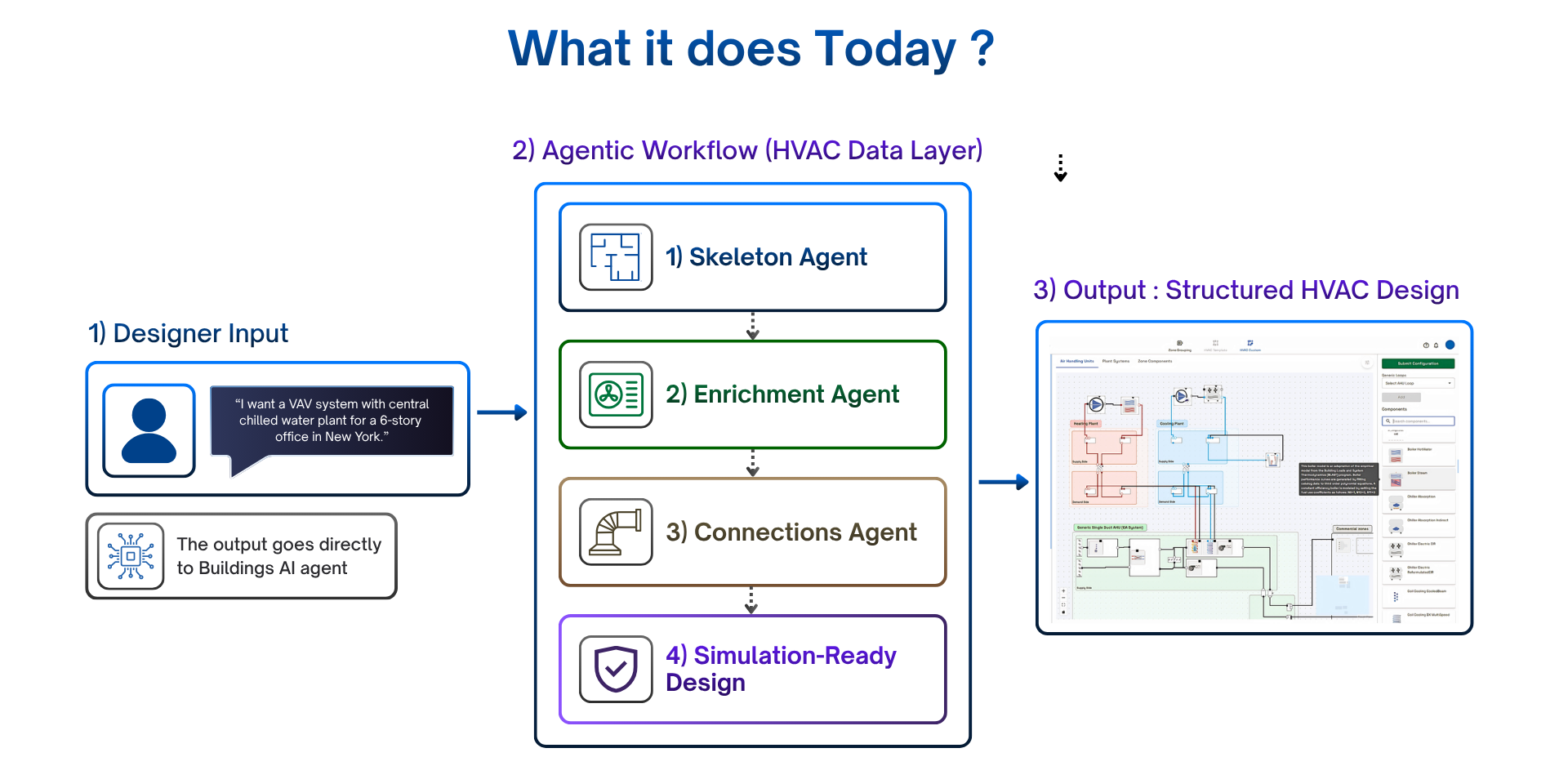
We didn't try to rebuild the platform. We picked one feature — HVAC design — with a deliberately narrow goal: build a workflow that only understands the data layer. No UI concerns. No application layer concerns. Just an agentic workflow that could read from the real component database, apply HVAC domain rules, and produce a fully specified, technically valid design the simulation engine could consume directly. Every component identified and typed, every parameter in range, every connection correctly wired. No human cleanup passes.
The Shape It Took
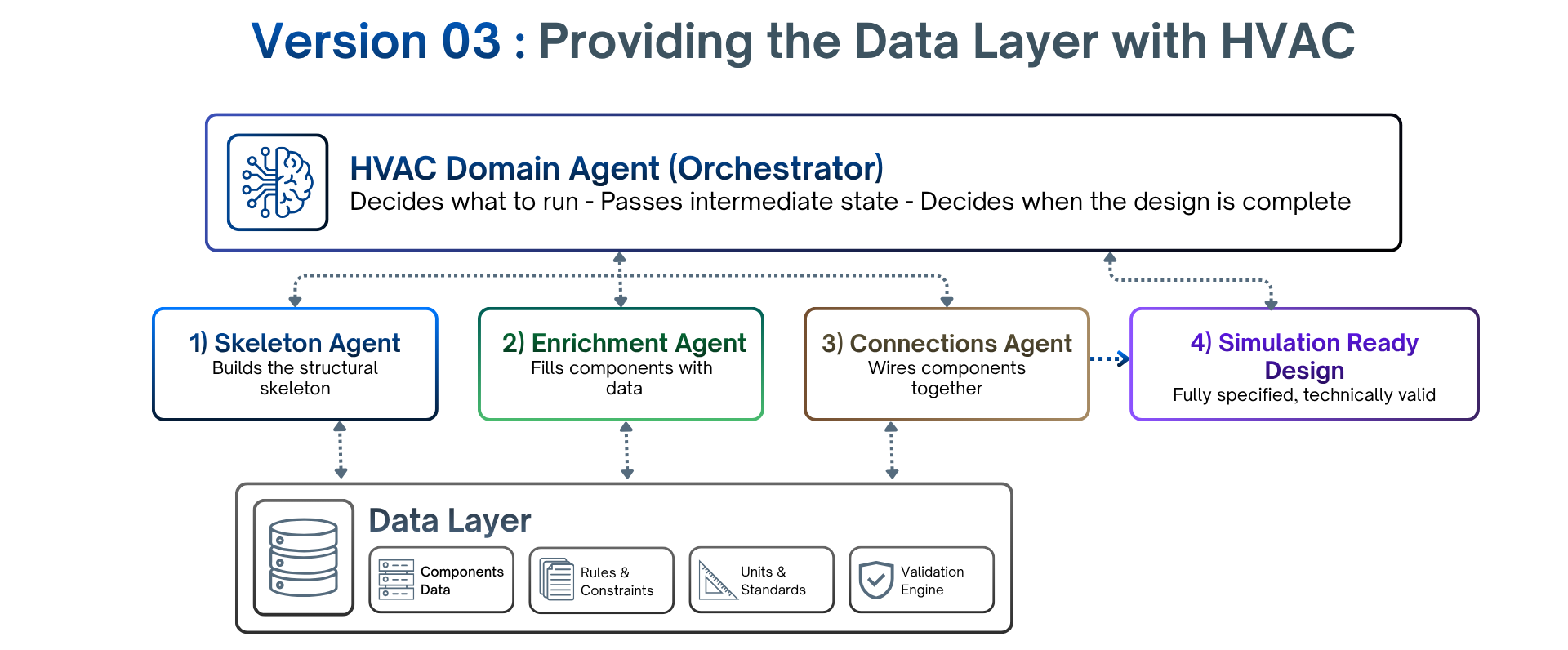
One agent wasn't enough. The work split into three distinct stages — each different enough that forcing them into a single agent would have reproduced exactly the bloated, do-everything component we'd just escaped in V2:
A Skeleton Agent that builds the structural skeleton — what components exist, their types, their hierarchy.
An Enrichment Agent that takes that skeleton and fills each component with the right parameters from the component database.
A Connections Agent that wires the enriched components together, applying topology rules across systems.
Above the three sits the HVAC Domain Agent, orchestrating the workflow — deciding what runs when, passing intermediate state, deciding when the design is complete.
The Debt We Knowingly Took On
A domain agent for orchestrating subagent is structurally close to V2's supervisor — the pattern we just finished explaining why we abandoned. We know.
The difference is real: V2's supervisor was a global orchestrator coordinating across unrelated domains through APIs. The HVAC Domain Agent is scoped to a single domain; its subagents own their data directly; the blast radius is bounded; the coordination is local. That's not the same failure mode.
But it's also not the final shape. Ideally the domain agent shouldn't do orchestration at all — that concern belongs above the data layer, not inside it. We accepted this as technical debt, deliberately, in exchange for focusing on the harder question: whether the data layer itself could be built cleanly. In a later stage we pull the orchestration out, and the three-plus-one becomes a complete, self-contained data layer. The HVAC Domain Agent goes back to being what it should be — a domain expert, not a workflow manager.
Naming the debt explicitly matters. Unacknowledged drift back to old patterns is how architectures rot. Acknowledged debt has an exit plan.
What It Does Today
A designer describes an HVAC system in natural language; the workflow produces a structured design with the correct component hierarchy — parents, children, all parameters drawn from the real component database, all connections wired correctly. Full chain from intent to validated output, against real design patterns, not toy ones.
What Surprised Us
The hardest part wasn't the LLM reasoning. It was a data contract. Getting agents to produce output that was schema-valid, semantically valid, topologically valid, and parametrically valid took far more iteration than the prompting. The models rarely were bottlenecks. The interface between the models and the rest of the system was.
Splitting into three agents forced decisions, we'd otherwise have deferred. The Skeleton Agent couldn't quietly do parameter work to make its life easier. The Enrichment Agent couldn't quietly assume a connection. Each handoff had to be a real contract because the next agent couldn't reach back across the boundary. The result is far more debuggable — when something goes wrong, it's immediately obvious which agent in the chain is responsible for.
And: structured data beats clever prompting. The work that paid off was in the data layer and the contracts between agents, not in the prompt layer.
What's Still Open
The orchestration debt is obvious. Beyond that: how the clean data layer hands off to UI agents and other domain agents is still being designed. Human-in-the-loop is open — where does a human need to be in the loop, and how does the agent know to ask at the right moment? Ambiguous input remains hard. When the user's description is underspecified, the right recovery path isn't always obvious. We have heuristics. We don't yet have a principle.
What's Next
The HVAC data agent is the first chain in a much larger architecture. The immediate next step is pulling orchestration out of the domain agent, so the data layer becomes a complete, self-contained "three plus one" — V3's technical debt coming due. After that, connecting it to UI agents so a designer sees the HVAC system appear visually as it's being built, closing the loop between intent, structure, and surface.
The longer arc is multi-domain. Buildings AI already has envelope agents from V1 and V2; bringing them under the new ownership model is on the roadmap, alongside new domain agents for electrical and plumbing. The end state is a building design system where each domain agent owns its piece, and they collaborate on a shared design.
The open question we're most interested in: how do agents negotiate when their domains overlap? HVAC and electrical care for load. Envelopes and HVAC both care about thermal performance. Structural and everything else both care about where things physically go. The ownership model is clean when domains are disjointed and gets interesting fast when they're not. That's the coordination problem we'll be writing about next.
Takeaways
Isolated agents don't compose. Individual capability is not collective intelligence. V1 agents were each competent — together they produced contradictions, because nothing tied them. Orchestration is not optional.
API coupling is a slow poison. It looks abstract. It is a hidden dependency that becomes load bearing over time. V2 was hardest to change in precisely the area we needed to change most.
Agents need ownership, not just responsibility. An agent that can only act on what it's said isn't autonomous — it's a subroutine. Real agencies require authority over data. This is the single biggest shift between V2 and V3.
Single responsibility applies to agents, not just functions. The same reasoning that says a class shouldn't have too many reasons to change applies to agents. V2's supervisor was a god class with a prompt. We are not going back.
Pick your hardest problem first. Validating a new architecture on the easy case is how you find out, six months later, that it doesn't generalize.
Name the debt you take on. V3's domain-agent-as-orchestrator is real debt, taken deliberately in exchange for focus on the data layer. Acknowledged debt has an exit plan.
Closing
We don't think we've solved agentic AI for the built environment. We think we've finally found the right foundation to solve it on. The difference between V1 and V3 is not cleverness — it's humility. We stopped trying to build one smart system and started building a set of focused, honest agents that know their limits.
The architecture is better. It is not finished. The orchestration debt in V3 is real; the handoffs between agent types are still being designed, and the hardest problem — coordination across overlapping domains — is in front of us, not behind.
If you're building agentic systems and feeling the weight of growing complexity, the question worth sitting with is not "how do I make my agents smarter?"
It is: "what do my agents own — and is that ownership clean?"
Take the Next Step: Start Your Free Trial or Book a Demo
Comments
Recent posts